

اگر مهندس نرمافزار هستید، ممکن است خیلی در مورد معماریها مطالعه کرده باشید. میتوان به معماری Layered به عنوان یکی از محبوبترین معماریها اشاره کرد. معماریهای زیادی با همین ایده معرّفی شدهاند. معماری Clean از جملهی همین معماریها است.
ما در صباویژن به تازگی معماری کلین را برای سرویس بکند پیادهسازی کردهایم. در این نوشته به صورت مختصر از تجربهها، چرایی و چالشهایی که برایمان وجود داشته نوشتهام.
چرا به پیادهسازی معماری کلین فکر کردیم؟
یکی از مهمترین دلایل برای اجرای معماری کلین در پروژه صباویژن آشفتگی و بینظمی منطقهای نوشته شده است. این آشفتگی بهدلیل تغییرات بسیار زیاد بیزینس و تعدّد پیادهسازیهایی که وجود داشته، به وجود آمده است.
وقتی که توسعهدهندهی جدیدی به تیم اضافه میشود، مراحل آمادهسازی وی توسط مدیر تیم انجام میشود. امّا چه اندازه با جزئیات میتوان کل پروژه را برای نیروی جدید توضیح داد؟
مطمئناً اگر پروژه ساختار یکپارچه و منظمی نداشته باشد، احتمالاً نیروی جدید با سختیهای بسیاری روبهرو خواهد شد.
برای جلوگیری از بینظمی پروژه راههای مختلفی وجود دارد: تنظیم سندهایی درونتیمی که کل تیم به آن متعهّدند، استفاده از معماریهای نرمافزاری و رعایت کداستایل واحد.
این مشکلات فقط مختص به نیروی جدید نیست، بلکه حتّی نیروهای با سابقه نیز گاهی دچار مشکل و پیچیدگی میشوند که این برای تیم نرمافزاری و شرکت بسیار بد است.
به لطف ابزارهای اصلاحکننده، کداستایل پروژه از نظر نظم ظاهری یکپارچه میشود. امّا مشکل از جایی شروع میشود که برای فهمیدن نحوهی کارکرد منطق یک قسمت از پروژه باید حجم بزرگی از کد را در قسمتها و ماژولهای مختلف مورد بررسی قرار دهیم. هرچند گاهی اوقات به سختی میتوان حتّی منطق کد نوشتهشده را درک کرد. حال هرچه پروژه بیشتر توسعه داده شود پیچیدگی بیشتر خواهد شد. در حقیقت معماری کلین در باطن خودش یکپارچگی و نظم را وارد نرمافزار میکند.
منظور از نظم و یکپارچگی صرفاً ساختاربندی پوشهها و قراردادن ماژولها در جای خود نیست! برای پیادهسازی معماری کلین باید Data Flow بین لایههای مختلف نرمافزار همیشه بهدرستی برقرار باشد. باید لایههای درونیتر هیچ وابستگی به لایههای بیرونی نداشته باشند. باید همیشه لایههای بیرونی به لایههای درونی وابستگی داشته باشند و بسیاری از موارد دیگری که رعایتشان ضروری است.
حال اگر موارد اساسی را به درستی و بدون نقص رعایت کردید، نظم و یکپارچگی به طور کامل وارد نرمافزارتان خواهد شد. امّا با این حال، نباید از ساختاربندی پوشهها و قوانین نامگذاری غافل شد.
آیا شما نیاز به معماری کلین دارید؟
اگر درحال راه اندازی MVP استارتاپ هستید، همین الان به شما میگویم که خیر! اگر محصولی دارید که به بلوغ خودش رسیده و در حال حاضر به فکر قدرت بیشتر در توسعه و یکپارچگی در نرمافزارتان هستید، معماری کلین میتواند خیلی به شما کمک کند.
در کل برای پیادهسازی معماری کلین، زمان و هزینههای زیادی را باید در نظر داشته باشید. در مراجع، نسخه از پیش تعیین شدهای برای پیادهسازی وجود ندارد و شما باید طبق نیازمندیهای پروژه و براساس راهنماییها و مفاهیم موجود معماری مورد نظر خود را طراحی کنید.
توضیحاتی در مورد معماری کلین
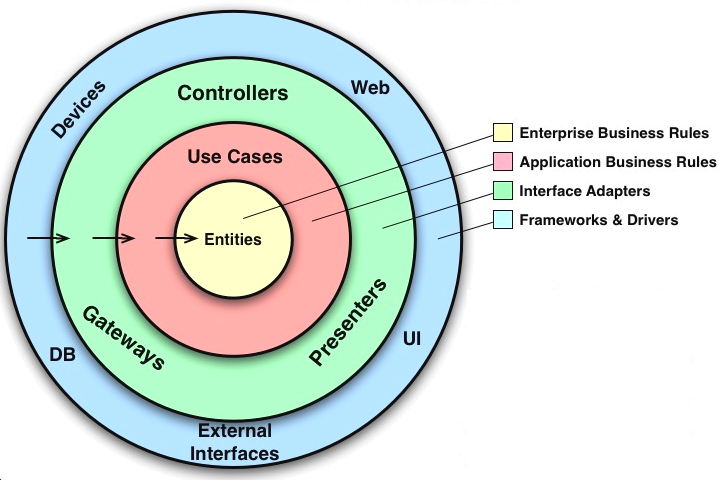
اگر در مورد معماریهای Layered مطالعه داشته باشید متوجّه میشوید که از لحاظ مفاهیم خیلی به هم شبیه هستند. برای مثال، معماری Hexagonal یا Port Adapter چندسالی قبل از معماری کلین معرفی شدند امّا در باطنشان کاملاً یک چیز را مطرح میکنند و آنهم رعایت وابستگیهاست.
حالا منظورمان از رعایت وابستگیها چیست؟
معماری کلین سه لایه را معرفی میکند که عبارتند از: Use Case ،Presentation ،Entity
در حقیقت هرکدام از این لایهها باید کاملاً از هرچیزی که خارج از آنها وجود دارد ایزوله باشند. لایههای درونی نباید هیچ وابستگیای به بیرون داشته باشند، درحالیکه لایههای بیرونی میتوانند وابستگی به لایههای درونی داشته باشند و از آنها استفاده کنند. رعایت این وابستگیها مهمترین عامل برقراری معماری کلین هست. وظیفه هرکدام از لایهها به شرح زیر هست:
- Entity:
- درونیترین لایه (نباید هیچ وابستگیای به بیرون داشته باشد) است. در حقیقت این لایه یک موجودیّت (میتواند فانکشن یا دیتاکلاس باشد) است که Business Rules را درخود دارد.
- این لایه از هرگونه تغییر در دنیای بیرون ایزوله است. برفرض مثال، اگر نحوه صفحهبندی (Pagination) را بخواهیم تغییر دهیم این لایه نباید تحت تاثیر قرار گیرد.
- اگر بخواهیم با لایههای مختلف یا سرویسهای خارجی مثل دیتابیس یا سرویس بروکرها حرف بزنیم باید از این لایه برای انتقال داده استفاده کنیم.
- ورودی آرگومان و خروجی لایه های مختلف از جنس Entity میباشد و زبان مشترک بین لایه های مختلف میباشد
- Use Case:
- شامل منطق کسب و کاریمان است که یک لایه بیرونتر از مدل است. در این لایه مفهومی به نام Use Case معرفی خواهد شد که وظیفه آن چیزی شبیه کنترلرها در معماری MVC یا View در معماری MVT است.
- این لایه وظیفه انتقال داده از entity به بیرون و از لایههای بیرون به entity را دارد.
- Presentation:
- این لایه بیرونیترین لایه در معماری کلین است و وظیفه ارائه و یا گرفتن داده از کاربر را دارد. در وب سرویسها میتوان آن را به Serializerها تشبیه کرد.
نکتهای که باید به آن دقت کرد این است که بسته به نیاز شما این تعاریف از لایهها ممکن است که تغییر کند و شما نباید محدود به این تعاریف باشید. تنها باید پایبند به قوانین وابستگی در این لایهها باشید.
اینکه میگوییم نباید هیچکدام از لایهها از لایههای دیگر خبر داشته باشند چه معنیای میدهد؟
یعنی اگر برفرض مثال در لایه Presentation خواستیم تغییری ایجاد کنیم، نباید این تغییر به لایههای داخلی وابسته باشد و باید بتوان به شکل مستقل منطقها را تغییر داد. با این اوصاف ما هیچ وابستگیای به فریمورک یا رابط کاربری یا حتّی دیتابیس و انواع سیستمهای خارجی مثل Messagin-Queueها و … نداریم.
در نتیجه، بهراحتی میتوانیم از جنگو به فلسک سوییچ کنیم، یا اگر تصمیم به تغییر RabbitMQ به Apache Kafka داشته باشیم به راحتی بتوانیم این تغییرات را انجام دهیم و فقط اینترفیسهایی که با سیستمهای خارجی در ارتباط هستند را باید تغییر داد.
معماری کلین چه مزایایی را به ما اضافه میکند؟
– مستقل از فریمورک، دیتابیس، رابط کاربری و سیستمهای خارجی
همانطور که گفتیم بنیادیترین اصل معماریهای نرمافزاری رعایت وابستگیهاست.
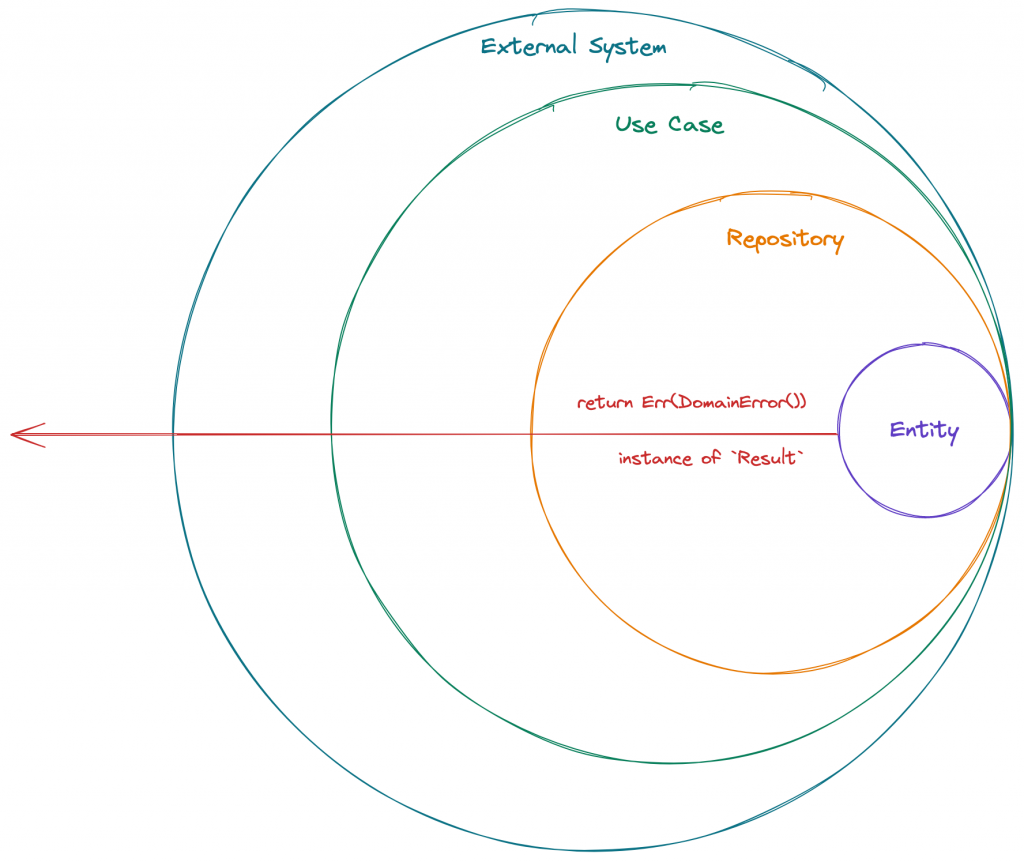
لایههای معماری کلین در حقیقت مانند دایرههایی متحدالمرکز هستند که هر یک وظیفهای از قسمتهای مختلف از نرمافزار ما را برعهده گرفتهاند. قانونی برای وابستگیها در معماری وجود دارد که بیان میکند که تنها لایه های بیرونی میتوانند به لایههای درونی وابسته باشند. و جهت وابستگی از بیرون به درون است. یعنی لایههای درونی نباید هیچ اطلاعاتی از لایههای بیرون داشته باشند. نباید فانکشن یا متغیر یا کلاسی از لایههای بیرون در لایههای درونی صدا زده شود یا فراخوانی شود. اگر این اتفاق بیافتد یعنی شما قانون وابستگی را نقض کردهاید و منتظر اتفاقاتی بدی که در ادامه توسعه برایتان خواهد افتاد باشید.
بر فرض مثال اگر فریمورکمان جنگو است، نباید در Use Caseها وابستگی به جنگو داشته باشیم! یک روش خیلی ساده که من برای خودم تعریف کردم تا بتوانم رعایت وابستگی را چک کنم این است که اگر بالای هر فایلی که در داخل لایههای درونی است (در اینجا Use Case)، ایمپورتی از لایهی بیرونی (در اینجا فریمورک) را ببینید، بدانید که وابستگیها را رعایت نکردهاید! مثلاً من نباید با این صحنه مواجه شوم:
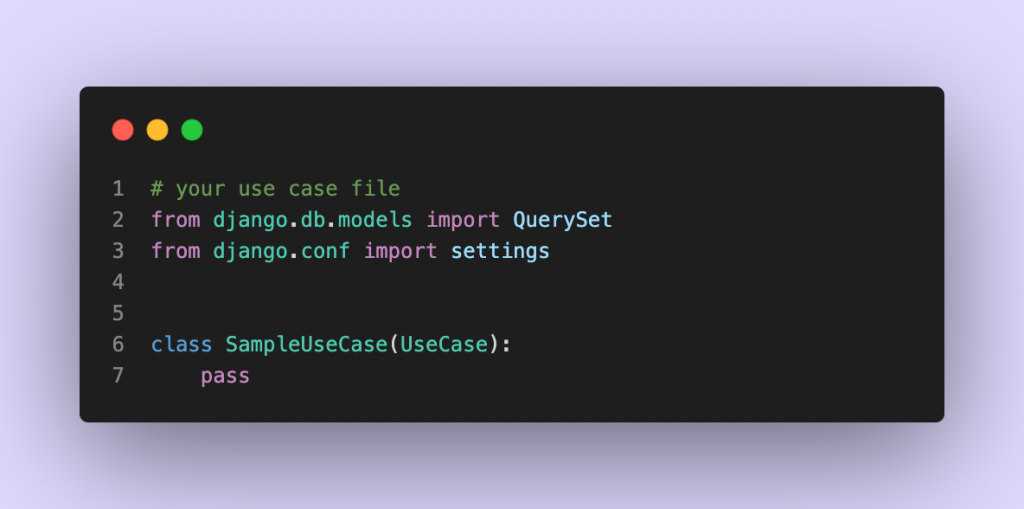
خب! پس اگر هیچ وابستگی به فریمورکی که استفاده میکنیم نداشته باشیم، به راحتی میتوانیم فریمورکمان یا حتّی دیتابیسمان را عوض کنیم. حتّی میتوانیم کد را در محیط cli اجرا کنیم بدون اینکه چیزی را بازنویسی کنیم.
در خیلی از پروژههای بزرگ این اتفاق میافتد که با بزرگ شدن مقیاس بیزینس، بعضی از ابزارها دیگر مناسب مقیاس نیستند و مجبور میشویم تا سریعترین راهحل و بهترینش (با توجّه به شرایط پروژه) را انتخاب کنیم. اگر در نرمافزار ما، مدیریت وابستگیها به درستی رعایت شده باشد پس نباید هیچ نگرانی از تغییر تکنولوژیها داشته باشیم زیرا در کوتاهترین زمان ممکن میتوان این اتفاق را رقم زد. برای مثال تجربه نتفیلیکس از تغییر Json Api به GraphQL در کمتر از ۲ ساعت میتواند گواه این قدرت باشد. حال دیگر محدود به امکانات فریمورکی که انتخاب میکنید نیستید و از فریمورک به عنوان یک ابزار استفاده میکنید! برای مثال ما در صباویژن از جنگو به منظور مدیریت کردن ریکویستها، روتینگ و همچنین ORM قدرتمندی که دارد، داخل معماری کلین استفاده میکنیم.
– هرچیزی قابل تست است
به خاطر عدم وابستگی به دیتابیس، فریمورک، رابط کاربری و سیستمهای خارجی به راحتی میتوانیم برای قسمتهای مختلف نرم افزارمان تست بنویسیم. همیشه تیم نرمافزاریای قدرتمندتر و چابکتر است که تستهای قویتر و قابل اطمینانتری داشته باشد.
برای مثال میخواهیم تستی برای درست عمل کردن کد تخفیف و سناریوی درگاه پرداخت بنویسیم. احتمالاً اولین چیزی که به ذهنتان میرسد نوشتن اینتگریشن تست است. امّا ما در معماری کلین به دلیل اینکه از Repository Pattern استفاده میکنیم به راحتی میتوانیم برای سیستمهای خارجی (دیتابیس، Messaging Queue، سرویس پیامک، API بانک و …) Fake Repository بنویسیم. در حقیقت با Repository Pattern ما خودمان را یک لایه از سرویسی که استفاده میکنیم جدا میکنیم و Data structure ورودی و خروجیمان را تعیین میکنیم. حال وقتی که Fake Repository را فراخوانی میکنیم میتوانیم بدون نیاز به سرویس اصلی، کدمان را اجرا و تست کنیم.
چالشهای اصلی ما در پیادهسازی معماری کلین
– داکیومنت کردن کد و Rest Api
ما برای داکیومنت کردن کدها به راحتی از ابزار sphinx استفاده کردیم. امّا برای داکیومنت کردن APIها چالش سختتری پیش رو داشتیم. به دلیل اینکه دیگر از سریالایزرهای جنگو استفاده نمیکنیم دیگر نمیتوانیم از ابزارهای آمادهای که برای داکیومنت کردن جنگو وجود دارد استفاده کنیم. پس باید دنبال راه حلی باشیم.
ما برای سریالایز کردن و اعتبارسنجی ریکویست و ریسپانسها از کتابخانهای به نام marshmallow استفاده کردیم. این کتابخانه خیلی مشابه سریالایزر جنگو است و مزیّت مضاعفی که دارد این است که کتابخانهی دیگری وجود دارد که میتواند از این سریالایزرها، خروجی openapi استخراج کند. خب تقریباً نصف کار انجام شد و حال کافی است اسکریپتی بنویسیم تا با کاوش در درون پوشههای مربوط، داکیومنتهای مورد نیاز را کنار هم بگذارد و خروجی openapi را به طور خودکار بسازد.
– مدیریت خطا
به دلیل لایه لایه بودن معماری، مدیریت کردن ارورها باید به درستی مهندسی شود. برای مثال اگر اروری در داخلی ترین لایه وجود داشته باشد، باید به درستی و بدون هیچ مشکلی به بیرونی ترین لایه منتقل شود . برای انجام این وظیفه ما از ابزار Result استفاده کردیم. این کتابخانه از الگوی مدیریت ارورها از زبان Rust الهام گرفته است. و برای حفظ یکپارچگی ارورها باید کلاسی تعریف کنیم که تمام ارورها را از آن مشتق بگیریم. برای مثال ما دیتاکلاس DomainError را بعنوان پایه ی ارورهای معماری درنظر گرفته ایم و بقیه ی ارورها را از آن مشتق گرفته ایم.
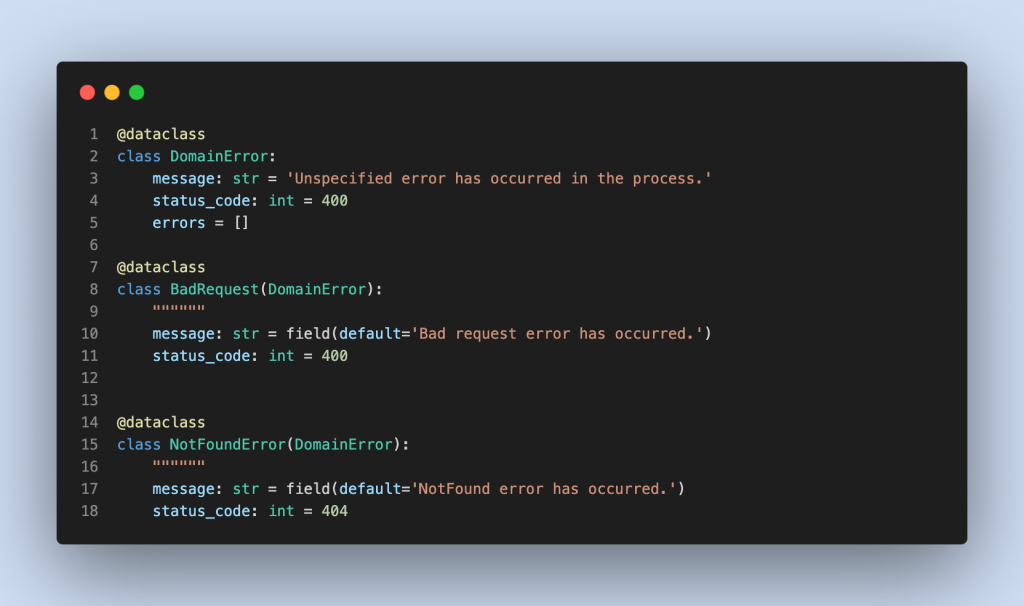
حال با استفاده از کتابخانه ریزالت ما این ارورها را از لایه های داخلی به لایه های بیرونی انتقال میدهیم.
فرض کنید موجودیتی به نام Book داریم و برای اعتبارسنجی فیلدهای آن اینگونه نوشته ایم:
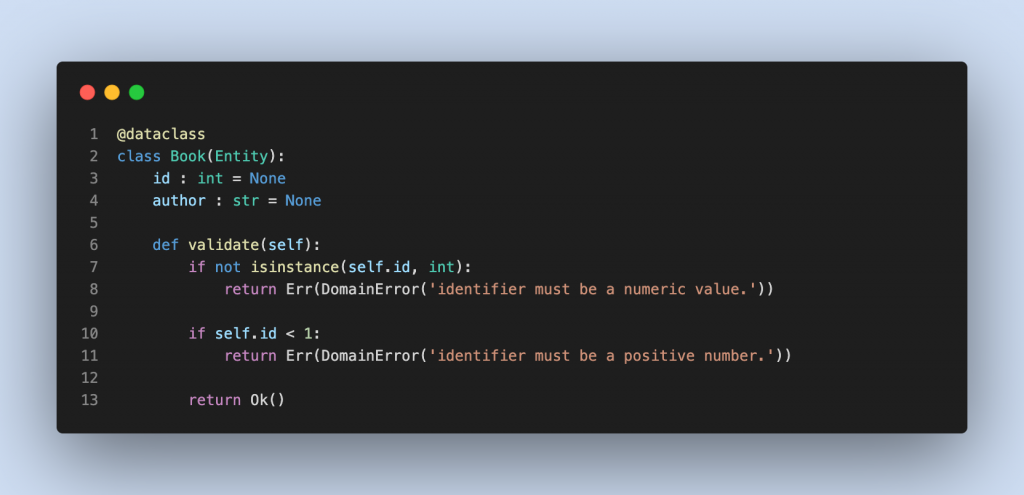
موجودیت کتاب را با استفاده از تابع create_book_entity ایجاد میکنیم.
این تابع را فرض کنید وجود دارد و کارش ساختن یک موجودیت از جنس کتاب است. خروجی این تابع از جنس Result است.
اگر خروجی بازگردانده شده اروری داشته باشد آن را مدیریت میکنیم و مستقیم آن ارور را به لایه بیرونی تر هدایت میکنیم:
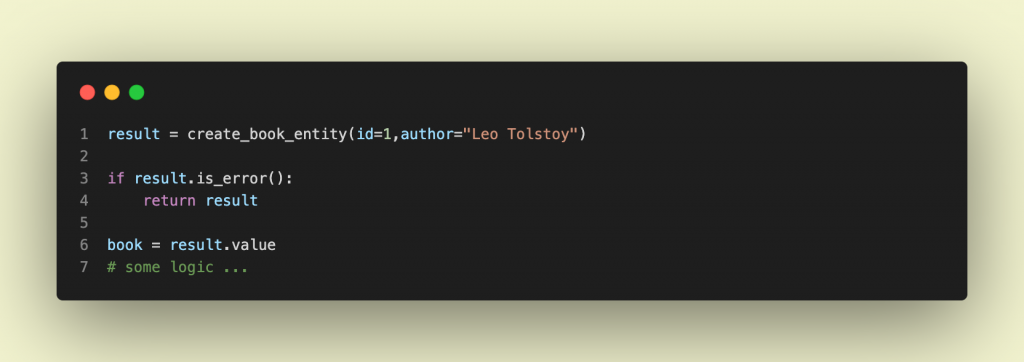
حال فرض کنید تمام لایه ها اینگونه ارورها را مدیریت کنند، پس دیگر مشکلی با تعداد لایههای زیادی که احتمالاً وجود خواهد داشت نداریم و اگر اروری وجود داشته باشد با آن بهراحتی برخورد میکنیم.
– تست نویسی
به خاطر جداسازی از هرگونه سیستمهای خارجی مثل دیتابیس و … ما امکان این را پیدا میکنیم که هرچیزی را بتوانیم تست کنیم، امّا پیادهسازی این کار همیشه به همین راحتی نیست. ما در داخل ریپازیتوریهایمان از ORM جنگو استفاده میکنیم، پیشتر دیدیم که ریپازیتوری پترن یک لایه ما را از سیستم خارجی جدا میکند و به تفکّر و ساختار دادهی مورد نظر خودمان با لایههای خارجی صحبت کنیم. در بالا من مفهومی به نام Fake Repository را معرفی کردم. یکم میخوام بیشتر در مورد این مفهوم حرف بزنم.
در حقیقت اگر در ریپازیتوری نیاز داشته باشیم تا لیست کتابهارا کامل دریافت کنیم این کار هم از طریق ریپازیتوری و هم از طریق فیک ریپازیتوری باید انجام شود و لیستی از کتاب هارا به ما دهد. تنها تفاوت این است که در ریپازیتوری اصلی دیتا از دیتابیس گرفته میشود ولی در فیک ریپازیتوری ما آرایهای داریم که داخلش موجودیتهایی از جنس کتاب هست و اگر بخواهیم عمل create را انجام دهیم کافی است به داخل این آرایه یک موجودیت از جنس کتاب، append کنیم.
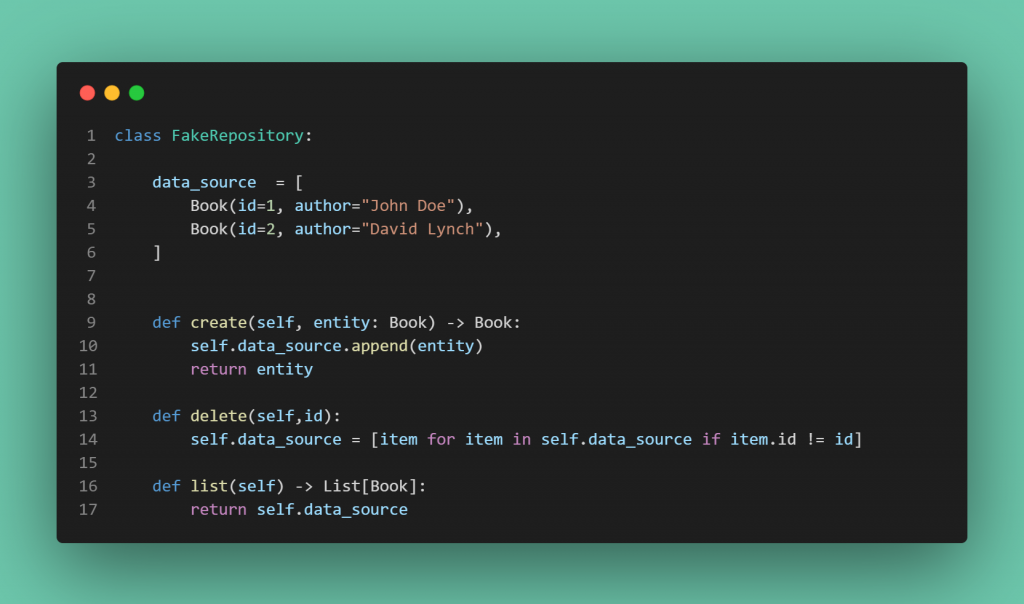
خب تا اینجا خیلی ساده میتوانیم فیک ریپازیتوری خودمان را پیاده سازی کنیم. امّا مشکل زمانی پیدا میشود که پروژه به شدّت پیچیده است و کوئریهای بسیار پیچیدهای داخل خود دارد. اگر بخواهیم متناظر هر ریپازیتوری و هر متد یکبار دیگر منطق موردنظر خودمان را با کارکردن با آرایه ها بنویسیم، یک دوباره کاری عظیمی انجام خواهد شد جدا از اینکه احتمال خطا هم خواهیم داشت. پس اینجا دنبال ابزاری دیگر بودیم تا بتوانیم به راحتی متد های orm جنگو را Mock کنیم و به لطف بزرگ بودن کامیونیتی پایتون و جنگو با این ابزار آشنا شدیم. با استفاده از این ابزار به راحتی میتوانیم فیک ریپازیتوری خودمان را مطابق با فیچرهای orm جنگو درست کنیم.
اشتباه رایج پیادهسازی معماری کلین در زبانهای Dynamic
اگر کمی داخل منابع و مقالات موجود درمورد معماری کلین کاوش کرده باشید، متوجّه میشوید که اکثر منابع در زبانهای Strong Type مانند جاوا و سیشارپ نوشته شده اند. امّا خیلی از دوستان را میبینم که وقتی میخواهند معماری را برای زبانهای dynamic همانند پایتون و PHP پیاده سازی بکنند کاملا با آن مانند زبانهای static رفتار میکنند، که این کاملا برای یک زبان dynamic اشتباه است.
برای مثال با حجم انبوهی از interface ها و struct ها در پایتون روبهرو میشویم که واقعا نیازی به آن نیست. به عقیده من وقتی از زبان dynamic استفاده میکنیم پس باید از فلسفه و قدرت پشت زبانهای dynamic به طور کامل بهره ببریم.
جمعبندی
در این نوشته سعی کردم چرایی و چالشهای پیاده سازی معماری کلین را مختصر توضیح دهم. آخرین توصیه من برای پیاده سازی معماری کلین این است که مفاهیم و قوانین پشت معماری را به طور کامل درک کنید. با توجّه به نیاز پروژه ممکن است ساختاری که میسازید شبیه مثالهای داخل منابع و کتاب معماری کلین نباشد، تنها چیزی که مهم است رعایت قوانین وابستگی و استقلال از سیستمها و Data Flowهاست.
پیادهسازی معماری کلین نیاز به هزینه و زمان زیادی دارد. باید در برنامهریزی کارها با دقّت زیادی به این مسئله توجّه کنید.